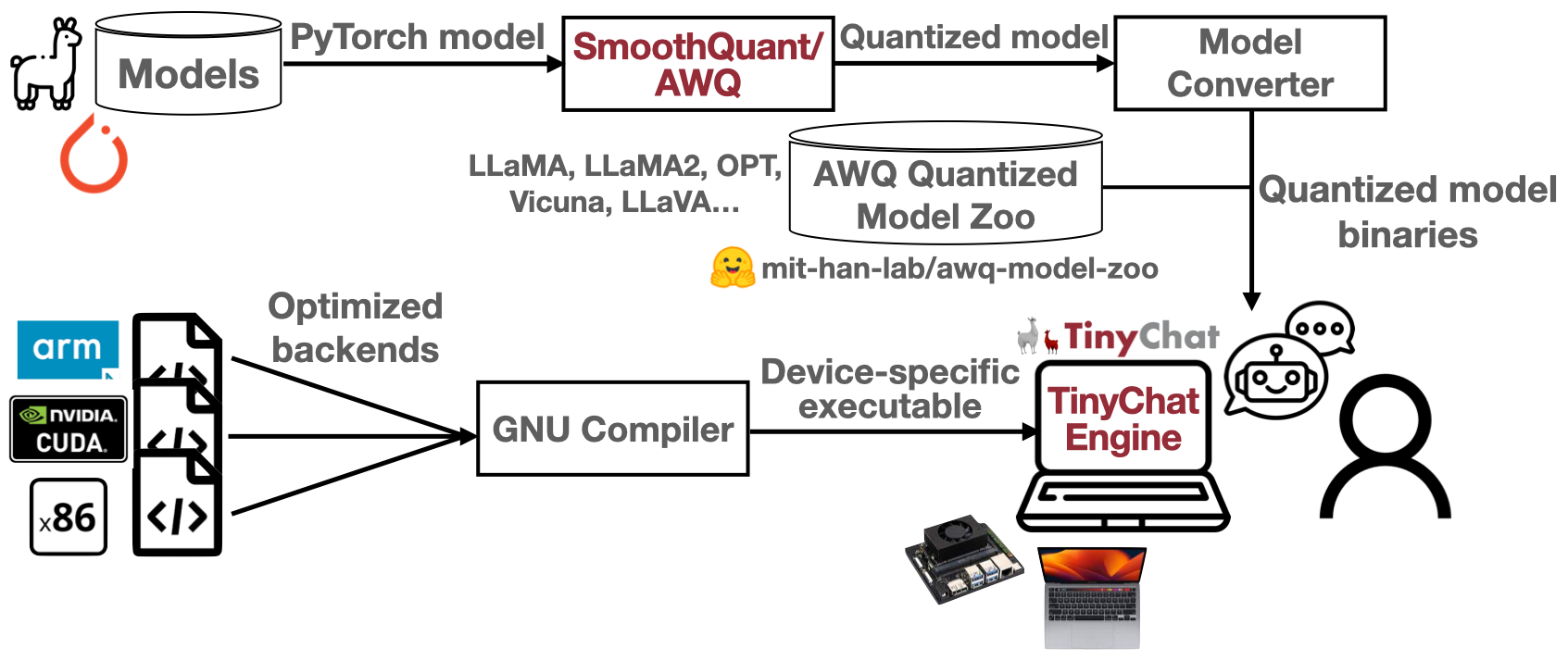
TinyChatEngine: On-Device LLM/VLM Inference Library
Running large language models (LLMs) and visual language models (VLMs) on the edge is useful: copilot services (coding, office, smart reply) on laptops, cars, robots, and more. Users can get instant responses with better privacy, as the data is local.
This is enabled by LLM model compression technique: SmoothQuant and AWQ (Activation-aware Weight Quantization), co-designed with TinyChatEngine that implements the compressed low-precision model.
Feel free to check out our slides for more details!
Code LLaMA Demo on NVIDIA GeForce RTX 4070 laptop:

VILA Demo on Apple MacBook M1 Pro:

LLaMA Chat Demo on Apple MacBook M1 Pro:

Overview
LLM Compression: SmoothQuant and AWQ
SmoothQuant: Smooth the activation outliers by migrating the quantization difficulty from activations to weights, with a mathematically equal transformation (100*1 = 10*10).
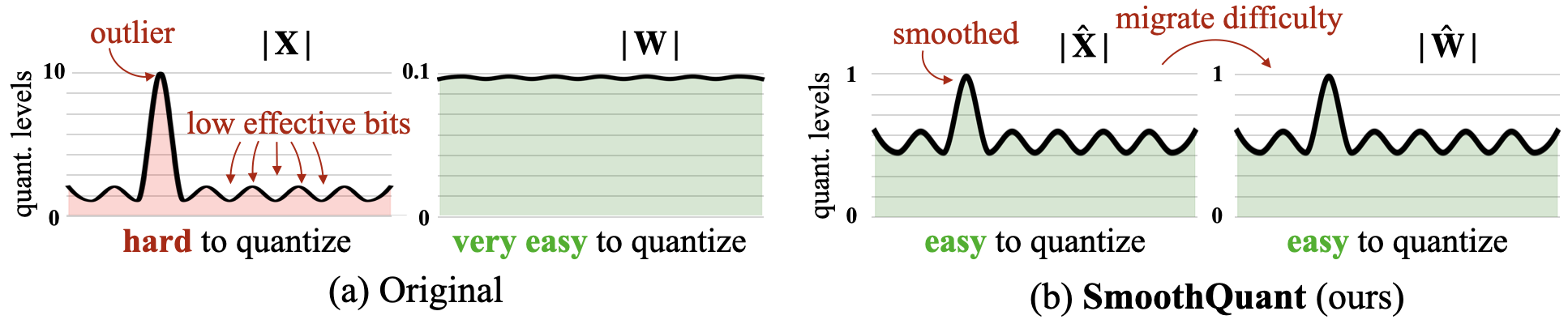
AWQ (Activation-aware Weight Quantization): Protect salient weight channels by analyzing activation magnitude as opposed to the weights.
LLM Inference Engine: TinyChatEngine
- Universal: x86 (Intel/AMD), ARM (Apple M1/M2, Raspberry Pi), CUDA (Nvidia GPU).
- No library dependency: From-scratch C/C++ implementation.
- High performance: Real-time on Macbook & GeForce laptop.
- Easy to use: Download and compile, then ready to go!
News
- **(2024/05)** 🏆 AWQ and TinyChat received the Best Paper Award at MLSys 2024. 🎉
- **(2024/05)** 🔥 We released the support for the Llama-3 model family! Check out our example and model zoo.
- **(2024/02)** 🔥AWQ and TinyChat has been accepted to MLSys 2024!
- **(2024/02)** 🔥We extended the support for vision language models (VLM). Feel free to try running VILA on your edge device.
- **(2023/10)** We extended the support for the coding assistant Code Llama. Feel free to check out our model zoo.
- **(2023/10)** ⚡We released the new CUDA backend to support Nvidia GPUs with compute capability >= 6.1 for both server and edge GPUs. Its performance is also speeded up by ~40% compared to the previous version. Feel free to check out!
Prerequisites
MacOS
For MacOS, install boost and llvm by
For M1/M2 users, install Xcode from AppStore to enable the metal compiler for GPU support.
Windows with CPU
For Windows, download and install the GCC compiler with MSYS2. Follow this tutorial: https://code.visualstudio.com/docs/cpp/config-mingw for installation.
- Install required dependencies with MSYS2
- Add binary directories (e.g., C:\msys64\mingw64\bin and C:\msys64\usr\bin) to the environment path
Windows with Nvidia GPU (Experimental)
- Install CUDA toolkit for Windows (link). When installing CUDA on your PC, please change the installation path to another one that does not include "spaces".
- Install Visual Studio with C and C++ support: Follow the Instruction.
- Follow the instructions below and use x64 Native Tools Command Prompt from Visual Studio to compile TinyChatEngine.
Step-by-step to Deploy Llama-3-8B-Instruct with TinyChatEngine
Here, we provide step-by-step instructions to deploy Llama-3-8B-Instruct with TinyChatEngine from scratch.
- Download the repo. git clone --recursive https://github.com/mit-han-lab/TinyChatEnginecd TinyChatEngine
- Install Python Packages
- The primary codebase of TinyChatEngine is written in pure C/C++. The Python packages are only used for downloading (and converting) models from our model zoo. conda create -n TinyChatEngine python=3.10 pip -yconda activate TinyChatEnginepip install -r requirements.txt
- The primary codebase of TinyChatEngine is written in pure C/C++. The Python packages are only used for downloading (and converting) models from our model zoo.
- Download the quantized Llama model from our model zoo. cd llm
- On an x86 device (e.g., Intel/AMD laptop) python tools/download_model.py --model LLaMA_3_8B_Instruct_awq_int4 --QM QM_x86
- On an ARM device (e.g., M1/M2 Macbook, Raspberry Pi) python tools/download_model.py --model LLaMA_3_8B_Instruct_awq_int4 --QM QM_ARM
- On a CUDA device (e.g., Jetson AGX Orin, PC/Server)
bash python tools/download_model.py --model LLaMA2_7B_chat_awq_int4 --QM QM_CUDA - Check this table for the detailed list of supported models
- On an x86 device (e.g., Intel/AMD laptop)
- *(CUDA only)* Based on the platform you are using and the compute capability of your GPU, modify the Makefile accordingly. If using Windows with Nvidia GPU, please modify
-arch=sm_xxin Line 54. If using other platforms with Nvidia GPU, please modify-gencode arch=compute_xx,code=sm_xxin Line 60. - Compile and start the chat locally. make chat -j./chatTinyChatEngine by MIT HAN Lab: https://github.com/mit-han-lab/TinyChatEngineUsing model: LLaMA_3_8B_InstructUsing AWQ for 4bit quantization: https://github.com/mit-han-lab/llm-awqLoading model... Finished!USER: Write a syllabus for the parallel computing course.ASSISTANT: Here is a sample syllabus for a parallel computing course:**Course Title:** Parallel Computing**Instructor:** [Name]**Description:** This course covers the fundamental concepts of parallel computing, including parallel algorithms, programming models, and architectures. Students will learn how to design, implement, and optimize parallel programs using various languages and frameworks.**Prerequisites:** Basic knowledge of computer science and programming concepts.**Course Objectives:*** Understand the principles of parallelism and its applications* Learn how to write parallel programs using different languages (e.g., OpenMP, MPI)...
Deploy vision language model (VLM) chatbot with TinyChatEngine
TinyChatEngine supports not only LLM but also VLM. We introduce a sophisticated chatbot for VLM. Here, we provide easy-to-follow instructions to deploy vision language model chatbot (VILA-7B) with TinyChatEngine. We recommend using M1/M2 MacBooks for this VLM feature.
- Follow the instructions above to setup the basic environment, i.e., Prerequisites and Step-by-step to Deploy Llama-3-8B-Instruct with TinyChatEngine.
- To demonstrate images in the terminal, please download and install the following toolkit.
- Install termvisage.
- (For MacOS) Install iTerm2.
- (For other OS) Please refer to here to get the appropriate terminal ready.
- Download the quantized VILA-7B model from our model zoo.
- On an x86 device (e.g., Intel/AMD laptop) python tools/download_model.py --model VILA_7B_awq_int4_CLIP_ViT-L --QM QM_x86
- On an ARM device (e.g., M1/M2 Macbook, Raspberry Pi) python tools/download_model.py --model VILA_7B_awq_int4_CLIP_ViT-L --QM QM_ARM
- On an x86 device (e.g., Intel/AMD laptop)
- (For MacOS) Start the chatbot locally. Please use an appropriate terminal (e.g., iTerm2).
- Image/Text to text ./vila ../assets/figures/vlm_demo/pedestrian.png
- There are several images under the path
../assets/figures/vlm_demo. Feel free to try different images with VILA on your device!
- There are several images under the path
- For other OS, please modify Line 4 in vila.sh to use the correct terminal.
- Image/Text to text
Backend Support
| Precision | x86 (Intel/AMD CPU) | ARM (Apple M1/M2 & RPi) | Nvidia GPU |
|---|---|---|---|
| FP32 | ✅ | ✅ | |
| W4A16 | ✅ | ||
| W4A32 | ✅ | ✅ | |
| W4A8 | ✅ | ✅ | |
| W8A8 | ✅ | ✅ |
- For Raspberry Pi, we recommend using the board with 8GB RAM. Our testing was primarily conducted on Raspberry Pi 4 Model B Rev 1.4 with aarch64. For other versions, please feel free to try it out and let us know if you encounter any issues.
- For Nvidia GPU, our CUDA backend can support Nvidia GPUs with compute capability >= 6.1. For the GPUs with compute capability < 6.1, please feel free to try it out but we haven't tested it yet and thus cannot guarantee the results.
Quantization and Model Support
The goal of TinyChatEngine is to support various quantization methods on various devices. For example, At present, it supports the quantized weights for int8 opt models that originate from smoothquant using the provided conversion script opt_smooth_exporter.py. For LLaMA models, scripts are available for converting Huggingface format checkpoints to our int4 wegiht format, and for quantizing them to specific methods based on your device. Before converting and quantizing your models, it is recommended to apply the fake quantization from AWQ to achieve better accuracy. We are currently working on supporting more models, please stay tuned!
Device-specific int4 Weight Reordering
To mitigate the runtime overheads associated with weight reordering, TinyChatEngine conducts this process offline during model conversion. In this section, we will explore the weight layouts of QM_ARM and QM_x86. These layouts are tailored for ARM and x86 CPUs, supporting 128-bit SIMD and 256-bit SIMD operations, respectively. We also support QM_CUDA for Nvidia GPUs, including server and edge GPUs.
| Platforms | ISA | Quantization methods |
|---|---|---|
| Intel & AMD | x86-64 | QM_x86 |
| Apple M1/M2 Mac & Raspberry Pi | ARM | QM_ARM |
| Nvidia GPU | CUDA | QM_CUDA |
- Example layout of QM_ARM: For QM_ARM, consider the initial configuration of a 128-bit weight vector, [w0, w1, ... , w30, w31], where each wi is a 4-bit quantized weight. TinyChatEngine rearranges these weights in the sequence [w0, w16, w1, w17, ..., w15, w31] by interleaving the lower half and upper half of the weights. This new arrangement facilitates the decoding of both the lower and upper halves using 128-bit AND and shift operations, as depicted in the subsequent figure. This will eliminate runtime reordering overheads and improve performance.
TinyChatEngine Model Zoo
We offer a selection of models that have been tested with TinyChatEngine. These models can be readily downloaded and deployed on your device. To download a model, locate the target model's ID in the table below and use the associated script. Check out our model zoo here.
| Models | Precisions | ID | x86 backend | ARM backend | CUDA backend |
|---|---|---|---|---|---|
| LLaMA_3_8B_Instruct | fp32 | LLaMA_3_8B_Instruct_fp32 | ✅ | ✅ | |
| int4 | LLaMA_3_8B_Instruct_awq_int4 | ✅ | ✅ | ||
| LLaMA2_13B_chat | fp32 | LLaMA2_13B_chat_fp32 | ✅ | ✅ | |
| int4 | LLaMA2_13B_chat_awq_int4 | ✅ | ✅ | ✅ | |
| LLaMA2_7B_chat | fp32 | LLaMA2_7B_chat_fp32 | ✅ | ✅ | |
| int4 | LLaMA2_7B_chat_awq_int4 | ✅ | ✅ | ✅ | |
| LLaMA_7B | fp32 | LLaMA_7B_fp32 | ✅ | ✅ | |
| int4 | LLaMA_7B_awq_int4 | ✅ | ✅ | ✅ | |
| CodeLLaMA_13B_Instruct | fp32 | CodeLLaMA_13B_Instruct_fp32 | ✅ | ✅ | |
| int4 | CodeLLaMA_13B_Instruct_awq_int4 | ✅ | ✅ | ✅ | |
| CodeLLaMA_7B_Instruct | fp32 | CodeLLaMA_7B_Instruct_fp32 | ✅ | ✅ | |
| int4 | CodeLLaMA_7B_Instruct_awq_int4 | ✅ | ✅ | ✅ | |
| Mistral-7B-Instruct-v0.2 | fp32 | Mistral_7B_v0.2_Instruct_fp32 | ✅ | ✅ | |
| int4 | Mistral_7B_v0.2_Instruct_awq_int4 | ✅ | ✅ | ||
| VILA-7B | fp32 | VILA_7B_CLIP_ViT-L_fp32 | ✅ | ✅ | |
| int4 | VILA_7B_awq_int4_CLIP_ViT-L | ✅ | ✅ | ||
| LLaVA-v1.5-13B | fp32 | LLaVA_13B_CLIP_ViT-L_fp32 | ✅ | ✅ | |
| int4 | LLaVA_13B_awq_int4_CLIP_ViT-L | ✅ | ✅ | ||
| LLaVA-v1.5-7B | fp32 | LLaVA_7B_CLIP_ViT-L_fp32 | ✅ | ✅ | |
| int4 | LLaVA_7B_awq_int4_CLIP_ViT-L | ✅ | ✅ | ||
| StarCoder | fp32 | StarCoder_15.5B_fp32 | ✅ | ✅ | |
| int4 | StarCoder_15.5B_awq_int4 | ✅ | ✅ | ||
| opt-6.7B | fp32 | opt_6.7B_fp32 | ✅ | ✅ | |
| int8 | opt_6.7B_smooth_int8 | ✅ | ✅ | ||
| int4 | opt_6.7B_awq_int4 | ✅ | ✅ | ||
| opt-1.3B | fp32 | opt_1.3B_fp32 | ✅ | ✅ | |
| int8 | opt_1.3B_smooth_int8 | ✅ | ✅ | ||
| int4 | opt_1.3B_awq_int4 | ✅ | ✅ | ||
| opt-125m | fp32 | opt_125m_fp32 | ✅ | ✅ | |
| int8 | opt_125m_smooth_int8 | ✅ | ✅ | ||
| int4 | opt_125m_awq_int4 | ✅ | ✅ |
For instance, to download the quantized LLaMA-2-7B-chat model: (for int4 models, use –QM to choose the quantized model for your device)
- On an Intel/AMD latptop: python tools/download_model.py --model LLaMA2_7B_chat_awq_int4 --QM QM_x86
- On an M1/M2 Macbook: python tools/download_model.py --model LLaMA2_7B_chat_awq_int4 --QM QM_ARM
- On an Nvidia GPU: python tools/download_model.py --model LLaMA2_7B_chat_awq_int4 --QM QM_CUDA
To deploy a quantized model with TinyChatEngine, compile and run the chat program.
- On CPU platforms make chat -j# ./chat <model_name> <precision> <num_threads>./chat LLaMA2_7B_chat INT4 8
- On GPU platforms make chat -j# ./chat <model_name> <precision>./chat LLaMA2_7B_chat INT4
Related Projects
TinyEngine: Memory-efficient and High-performance Neural Network Library for Microcontrollers
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
Acknowledgement
Generated by